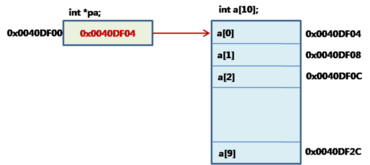
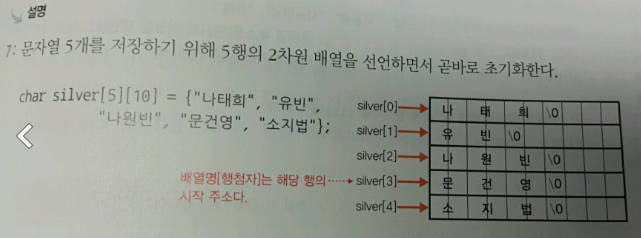
포인터를 사용하는 이유 - 참조 불가능한 변수를 간접적으로 참조 - 프로그램의 성능을 개선하고 기억 공간을 효율적으로 사용할 수 있다. - 동적 할당이 가능하다. (트리, 연결리스트에서 자세히) 포인터 사용 순서 1. 포인터 변수 선언 2. 포인터 변수에 다른 변수의 주소 대입 3. 간접 참조 연산자(*) 사용하여 포인터 변수 이용
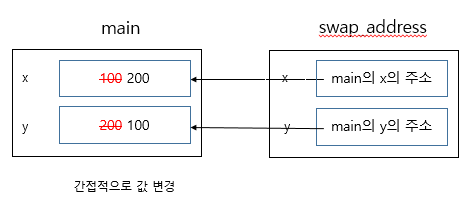
결론은 값에 의한 인자 전달은 함수에서는 값이 바뀌지만 main으로 돌아오면 그대로 주소에 의한 인자 전달은 함수에서 값 변경되어서 main으로 돌아와도 유지 이제 이유를 차근차근 살펴볼 차례
1. swap value함수 호출한 후 메모리
2. swap value함수 내부 실행
이때 swap value함수는 변경한 값을 돌려주지 못한다. void함수이고, return을 할 수 있는 int 함수로 변경한다고 해도 return 값은 1개이므로 변경된 2개의 값을 main으로 전달할 수 없다.
3. swap_value 함수 종료 후 기억 장소 리턴, main에 아무런 영향 주지 못하고 사라짐
4. swap_address함수 호출한 후 메모리
5. swap_address함수 내부 실행
6. swap_address함수 종료 후 기억장소 리턴, 사라짐
7. 메모리의 마지막 상태
※ 포인터와 문자열
C에서는 문자열 변수가 없다. 배열 or 포인터로 문자열을 표현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include<stdio.h>
#include<string.h>
int main()
{
char str1[10] ="language";
char*str2 ="language";
printf("배열 문자열 변경\n");
printf("%s->", str1);
strcpy(str1, "program");
printf("%s\n\n", str1);
printf("포인터 문자열 변경\n");
printf("%s->", str2);
str2 ="Cprogramming";
printf("%s\n\n", str2);
return0;
}
str1은배열의 시작 주소인 포인터 상수 주소변경이 불가능하므로 따라서 str1 = "문자열" 이 불가능하다.
str2는 문자열을 가리키는포인터 변수 원래 "language"가 저장되어 있는 공간을 가리켰는데 str2="문자열"로 다른 문자열이 저장되어있는 공간을 가리키게 할 수 있다. str1과 같은 배열의 문자열은 문자열 함수(strcpy)만을 이용해 전체 문자열을 변경하거나, 원소 하나하나 만을 변경할 수 있다.
기억공간의 차이
배열 문자열은 미리 개발자가 배열의 크기를 정해야 한다. 만약 배열의 크기가 20인데 "abc"라는 문자열을 저장한다면 '\0'문자를 포함하여 총 4개의 원소만 사용하고, 나머지 16개의 공간은 낭비가 된다. 포인터 문자열은 "abc"를 대입하면 '\0'을 포함하여 문자의 길이에 맞게 동적으로 할당된다. 동적 할당은 나중에 자세히
문제의 조건이 까다롭고, 뭔 말인지 모르겠다. 그냥 함수에서 내림차순 sorting 해서 입력받은 값까지 출력하면 되는 것 아닌가?
어려운 문제인지 알고 풀었는데 아니다..
문제20: 1~45 범위의 난수 6개로 구성된 로또 번호를 생성하는 프로그램을 작성하시오. 난수 6개는 no배열에 저장하되 6개의 난수가 서로 달라야 하며 화면에 출력될 때는 오름차순으로 정렬하여 표시한다. 사용자에게 생성한 로또 번호를 보여준 후에는 새로운 로또 번호의 생성 여부를 물어 사용자가 [ESC] 키를 누르면 더 이상 생성하지 않고 실행을 끝낸다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define N 6
void random_no(int*arr)
{
int i,j;
int flag=0; // 중복된 번호인지 확인
srand(time(NULL)); //시드값 설정
for (i =0; i < N; i++)
{
do
{
flag =0; //flag 0으로 초기화
arr[i] = (rand() % 45) +1; //번호 할당
for (j =0; j < i; j++)
{
if (arr[i] == arr[j]) //이전 번호와 중복이면
{
flag =1; //flag 1로 설정
break; //조건문 탈출, 위의 for문 탈출
}
}
} while (flag ==1); //flag가 1인동안 계속 반복
}
}
void sort(int*arr)
{
int i, j;
int temp;
for (i =0; i < N -1; i++)
{
for (j =0; j < N - i; j++)
{
if (arr[j] > arr[j +1])
{
temp = arr[j];
arr[j] = arr[j+1];
arr[j +1] = temp;
}
}
}
}
void print_lotto(int*arr)
{
int i;
printf("생성된 로또 번호:");
for (i =0; i < N; i++)
{
printf("%3d", arr[i]);
}
printf("\n");
}
int main()
{
int no[N]; //로또 번호 배열
do{
random_no(no);
print_lotto(no);
sort(no);
print_lotto(no);
printf("그만하려면 [ESC]키를, 새 로또 번호를 보려면 다른 키를 누르세요.\n");
왜 처음에 이상한 값 뜨는 거지? random_no 함수가 조금 생각해야 하는 부분 flag변수를 두어 배열에 같은 값이 있으면 flag를 1로 설정하여 while문을 계속 반복하면서 새로운 값을 부여하고 다시 확인하기 반복 로또 당첨되고 싶다. 일단 사지도 않는데 무슨 ㅋㅋ
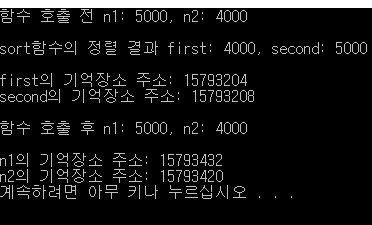
값에 의한 호출 방식으로 함수의 인자를 전달하면 main함수의 변수 값을 다른 함수에서 변경 할 수 없다. 결과를 확인하면 sort함수에서는 숫자가 오름차순으로 정렬이 되었으나 sort함수를 호출 하고 나서 main함수의 숫자는 정렬이 안된것을 확인 할 수 있다. 이유는 변수가 전혀 다른 변수이기 때문이다. 전혀 다른 변수라는것은 변수가 저장 되어있는 기억장소의 주소를 확인하면 알 수 있다. n1와 first의 변수의 주소가 다르다.
따라서 다른 함수에서 호출 한 함수의 변수를 변경하고 싶으면 변수의 주소를 함수에 전달하여야 한다!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include<stdio.h>
void sort(int*first, int*second)
{
int temp;
if (*first >*second)
{
temp =*first;
*first =*second;
*second = temp;
}
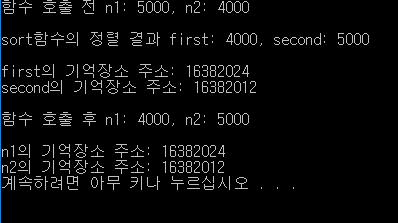
printf("\nsort함수의 정렬 결과 first: %d, second: %d\n\n", *first, *second);
printf("first의 기억장소 주소: %u\n", first); //&(*first)도 같은 표현
main에서 sort(&n1,&n2)로 변수의 주소 전달 sort함수는 main주소를 전달받았으므로 간접 참조 연산자*를 이용해 주소가 아닌 값을 받아올 수 있다. 결과를 보면 main함수의 변수들이 정렬된 것을 볼 수 있다. 주소를 확인하면 main함수의 변수와 sort함수의 변수가 같은 것을 확인할 수 있다. 주소를 전달받았기 때문이다.
추후 포인터를 공부한다면 좀 더 쉽게 이해할 수 있을 것이다.
※ 배열을 인자로 함수에 전달하기
배열명도 포인터이므로 포인터처럼 사용하여 인자로 전달하면 된다. 결론이지만 이해해보자 배열의 원소 하나를 함수의 인자로 전달하는 방식으로 모든 원소를 함수에 넣는다. 이 방법 번거롭고 많은 함수 호출이 일어난다. 일단 예제
max = find_larger(max, freeze[i]); 함수 호출할 때 freeze배열의 원소 하나하나 find_larger함수에 넣어서 최댓값을 찾는다.
처음에 max = find_larger[0] 로 지정해 놓았기 때문에 함수에는 1번 원소부터 넣어서
find_larger(max,freeze[1]) => 0~1중 큰 값이 리턴 find_larger(max,freeze[2]) => 0~2중 큰 값이 리턴 find_larger(max,freeze[3]) => 0~3중 큰 값이 리턴 find_larger(max,freeze[4]) => 0~4중 큰 값이 리턴 ... find_larger(max,freeze[9]) => 0~9중 큰 값이 리턴
총 9번 함수를 호출하여 큰 값을 구한다.
원소 하나하나 인자로 전달하는 방법은 상당히 비효율적이다. =>배열 전체를 인자로 전달한다. 포인터를 배우지 않았지만,배열명 = 포인터라고 알아두자 배열명인 freeze를 인자로 전달하면 배열 전체를 전달할 수 있다.
max = find_larger(freeze); freeze배열 전체를 인자로 전달하였다.
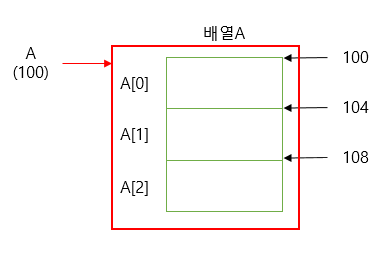
배열 이름인 freeze는 변수를 저장하고 있는 변수가 아니라 배열의 시작 부분을 가리키고 있는 주소와 같다. 위 그림을 보면 이해가 가능하다. freeze를 인자로 전달하여 freeze [0~9]까지 접근이 가능하게 된다.
-정리- 원소 하나하나를 전달하는 방법에 비해 훨씬 효율적인 방법 배열명을 인자로 전달하면 된다. 배열명은 배열의 첫 시작 원소의 주소이다.
※ 난수 구하기
난수구하기 은근히 자주 사용하는데 이참에 정리해보자 JAVA,C++,C#,C,PYTHON 배울 때 모두 사용한 거 같다 좀 자세히 정리해봐야지 C언어의 난수 생성함수 rand() : 0~32767 범위 안의 임의의 값 반환 헤더파일 stdlib.h(standard library 맞나?) 필요
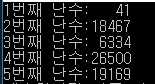
계속 같은 결과 나온다. 41,18467,6334,26500,19169 계속 이 순서... 난수 맞니??
씨드 설정 함수인 srand를 설정하여 난수가 순서를 변경한다. => 씨드가 같으면 생성되는 난수의 순서가 동일하다. default값은 1로 위에서 씨드를 설정하지는 않았지만 srand(1)로 설정이 되어있는 상태인 것이다. 하지만 씨드값을 프로그램을 실행할 때 매번 다르게 할 수 없다. time함수를 이용하여 현재 시간으로 씨드값을 설정하면 매번 다르게 자동적으로 씨드값을 설정할 수 있다. srand(time(NULL)) time 함수 사용하기 위해 time.h 헤더파일 필요
※ 스케일링 난수를 원하는 범위로 설정하는 방법 간단하다 rand() : 0~32767 이라고 했다. rand()%6 을 하면 0부터 5까지 나오겠지 그럼 (rand()%6)+1 을 하면 1부터 6까지의 범위가 나온다. (주사위) 5~10은 (rand%6)+5 일반화 min~max는 (rand%(max-min+1)) + min 간단한 게임 만들기 컴퓨터가 숨긴 수 맞추기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
//컴퓨터가 숨긴 1~100 중의 정수를 맞히는 게임
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
int main()
{
intbegin=1, end=100;
int count =0;
int computer, user;
srand(time(NULL)); //씨드 설정
computer = (rand() % (end-begin+1)) +begin; //컴퓨터가 숨기는 수 생성