이번 chapter는 정리해야 할 내용이 많아서 분리해서 정리하려 한다.
추가적으로 연습문제도 풀어보겠다.
내용 정리
이번에는 WHERE절이 무엇인지
WHERE 절에서 사용하는 AND와 OR 연산자
그리고 논리 연산자 외의 연산자들에 대해서 공부한다.
WHERE절
SELECT문으로 데이터를 조회할 때
특정 조건을 기준으로 원하는 행을 출력하는 데 사용
예를 들자면
앞 chapter에서 배운 것과 같이 테이블을 전체적으로 조회하는 것이 아니라
특정 조건에 맞는 테이블 내의 행만 조회하는 것이다.
부서 번호가 30인 사원, 보너스가 300만 원 이상인 사원 등
다양한 조건을 사용해서 원하는 데이터를 조회할 수 있게 하는 방법을 알아본다.
기본 문법
|
SELECT [조회할 열1 이름], ..., [조회할 열N 이름] FROM [조회할 테이블 이름]; WHERE [조회할 행을 선별하기 위한 조건식]; |
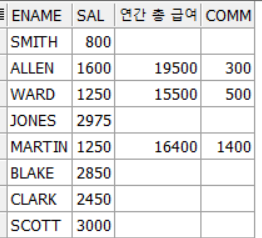
아래 표는 저번 chapter과 같이 계속 사용할 테이블의 전체 데이터이다.

이 테이블을 각종 조건을 이용하여
입맛에 맞게 조회해보자
EMP 테이블의 부서 번호가 30인 사원의 이름과 급여 부서 번호 조회
|
1
2
3
|
SELECT ENAME, SAL, DEPTNO
FROM EMP
WHERE DEPTNO = 30;
|

WHERE절에는 이용할 수 있는 다양한 연산자가 있는데
다양한 연산자들의 사용 방법에 대해 알아보겠다.
AND, OR 연산자
WHERE절에서 여러 개의 조건식을 지정하게 해주는 논리 연산자
비 전공자는 모르겠지만 나는 전공 자기에 논리 연산자의
자세한 설명은 PASS
EMP 테이블의 부서 번호가 30이고 직업이 'SALESMAN'인 사원의 정보
|
1
2
3
4
|
SELECT *
FROM EMP
WHERE DEPTNO = 30
AND JOB = 'SALESMAN';
|

AND 연산자를 통해 여러 개의 조건식을 사용할 수 있다.
여기서 주의할 점은
SQL은 대 소문자를 구별하지 않지만
JOB이라는 문자열 데이터는 테이블에 대문자로 들어있기 때문에
대문자로 검색해야 일치하는 행을 조회할 수 있다.
OR 연산자도 마찬가지로 여러 개의 조건식을 사용할 수 있도록 해준다.
산술 연산자, 비교 연산자
간단하게 말하면 사칙연산이다.
산술 연산자
간단하게 말하면 사칙연산이다.
+, -, *, /
비교 연산자
대소 비교 연산자(부등호)와 등가 비교 연산자가 있다.
대소 비교 연산자
| 연산자 | 사용법 | 설명 |
| > | A > B | A 값이 B 값을 초과할 경우 참 |
| >= | A >= B | A 값이 B 값 이상일 경우 참 |
| < | A < B | A 값이 B 값 미만일 경우 참 |
| <= | A <= B | A 값이 B 값 이하일 경우 참 |
등가 비교 연산자
| 연산자 | 사용법 | 설명 |
| = | A = B | A 값이 B 값과 같은 경우 참 |
| != | A != B | A 값이 B 값과 다를 경우 참 |
| <> | A <> B | |
| ^= | A ^= B |
EMP 테이블의 1년 급여(보너스 제외)가 36000 이상인 사원의 정보
|
1
2
3
|
SELECT *
FROM EMP
WHERE SAL * 12 >= 36000;
|

SAL * 12 와 같이 산술 연산자을 이용 할 수 있다.
또한 36000 이상인 사원을 조회하는 과정에서
비교 연산자인 부등호를 이용하였다.
논리 부정 연산자
부정문에 쓰이는 영어는 NOT
논리 부정 연산자는 NOT이다.
NOT은 '아닌 것'이라고 생각하면 된다.
EMP 테이블의 1년 급여(보너스 제외)가 36000이 아닌 사원의 정보
|
1
2
3
|
SELECT *
FROM EMP
WHERE NOT SAL * 12 = 36000;
|
WHERE SAL*12 != 36000과 같기 때문에
NOT은 혼자 잘 사용되지 않는다.
IN, BETWEEN, IS NULL과 같은 연산자에 복합적으로 사용된다.
또한 AND, OR과 같이 여러 조건식이 묶여있는 상황에서
정반대의 결과를 얻을 때 사용한다.
IN 연산자
IN 연산자는 특정 열에 해당하는 조건을 여러 개 지정하게 한다.
AND나 OR 연산자를 여러 번 사용하지 않게 하는 장점이 있다.
EMP 테이블의 JOB가 MANAGER OR SALESMAN OR CLERK인 사원의 정보
|
1
2
3
4
5
|
SELECT *
FROM EMP
WHERE JOB = 'MANAGER'
OR JOB = 'SALESMAN'
OR JOB = 'CLERK';
|
|
1
2
3
|
SELECT *
FROM EMP
WHERE JOB IN ('MANAGER','SALESMAN','CLERK');
|

두 코드는 같은 결과를 보여준다.
추후 중첩 쿼리문을 사용할 때도 유용하게 사용하는 연산자이다.
BETWEEN A AND B 연산자
연산자 이름처럼 A와 B 사이에 존재하는 값을 조회하기 위해 사용하는 연산자이다.
EMP 테이블의 SAL이 2000 이상 3000 미만인 사원의 정보
|
1
2
3
4
|
SELECT *
FROM EMP
WHERE SAL >= 2000
AND SAL <= 3000;
|
|
1
2
3
|
SELECT *
FROM EMP
WHERE SAL BETWEEN 2000 AND 3000;
|
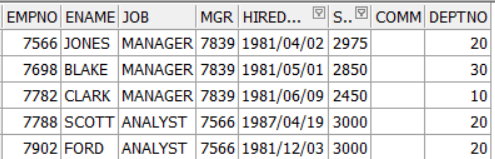
역시 같은 결과를 보여준다.
훨씬 간단하게 사이의 값에 존재하는 데이터를 확인할 수 있다.
LIKE 연산자와 와일드카드
LIKE 연산자는 일부 문자열이 포함된 데이터를 조회할 때 사용한다.
이때 와일드카드를 사용한다.
와일드카드는 _와 %가 있다.
_는 한 개의 문자 데이터를 의미하며
% 는 길이와 상관없는 모든 문자 데이터를 의미한다.
EMP 테이블의 사원 이름의 두 번째 글자가 L인 사원의 정보
|
1
2
3
|
SELECT *
FROM EMP
WHERE ENAME LIKE '_L%';
|

LIKE '_L%'의 의미는
두 번째 문자가 반드시 L이고
L 앞에는 반드시 한 문자가 와야 한다
L 뒤에는 몇 개의 문자가 와도 상관없다.
EMP 테이블의 사원 이름에 AM이 포함되어 있지 않은 사원의 정보
|
1
2
3
|
SELECT *
FROM EMP
WHERE ENAME NOT LIKE '%AM%';
|

이름에 AM이 포함돼있는 사원이 아닌 사원의 정보를 보여준다.
이때 AM은 붙어있어야 한다.
IS NULL 연산자와 집합 연산자는 다음 글에서 정리해보겠다.
'데이터베이스 > Do it 오라클로 배우는 데이터베이스 입문' 카테고리의 다른 글
| [Do it 오라클로 배우는 데이터베이스 입문] Chapter 4(SELECT문의 기본 형식) (0) | 2019.11.02 |
|---|---|
| [Do it 오라클로 배우는 데이터베이스 입문] Chapter 3(오라클 데이터베이스와 도구 프로그램 설치) (0) | 2019.10.26 |
| [Do it 오라클로 배우는 데이터베이스 입문] Chapter 2(관계형 데이터베이스와 오라클 데이터베이스) (0) | 2019.10.26 |
| [Do it 오라클로 배우는 데이터베이스 입문] Chapter 1(데이터베이스 개념) (0) | 2019.10.26 |